# 算法简介:
# TF:
TF 算法,全称 Term frequency,翻译过来就是词频,顾名思义,就是词的频率:
通常来讲,我们认为一个词出现的次数越多,那么该词语就越重要,但是,由于语言的特性,文章中包含许许多多停用词,虚词等无实际意义的词语,那么我们在对中文文本进行处理的时候,首先要对其进行一个预处理操作,去掉文章中的停用词等,以消除无实际意义的词产生的影响。
但是,由于一词多意及同义词的现象,单纯的词频统计往往在计算关键词的时候,出现一定的偏差,导致所得结果与实际情况差别较大。
词频指代的是一篇文章
# IDF:
IDF 算法,全称 Inverse Document Frequency,意译过来就是逆文档频率。
核心思想:
一个词语在文档中出现的次数越少,那么逆文档频率越大,即区分类别的能力越强,可以认为是关键词。
逆文档解释 (个人理解):
记总共有 m 个文档,有 n 个文档中包含了某一个词语,那么对于该词语的文档出现概率为:
假设一个词只在 100 篇文档中出现,但是由于文档数量过大 (例如 10000),那么该词语的文档频率就会非常的小 (1%),和 0 基本上没任何区别,也就是说,这个词和没出现的词没明显的差异,并不能做到对文档有很好的区分作用。
在此基础上,若我们取文档频率的倒数 (这里称为逆频率),那么上述提到的值就为 100,这样一来,就可以很好的消除未出现词的影响,以及对关键词有一个很好的区分作用。
但是,这样一来还是有问题,直接取倒数的话,得到的数据过于离散,在上述例子中,逆频率最少 (词只出现一次为 10000) 与最多 (词篇篇都出现 1) 的量级就会过大,在数学上,常用对数的方法,以消除量级过大的影响。
因此最终逆文档的公式:
补充:这里 + 1 的主要目的是为了消除未出现的词的影响 (使逆文档频率无穷大).
# TF-IDF
词频 - 逆文档频率,本质上就是 TF 和 IDF 的乘积,TF 的本质是要获取当前文章的高频词语,而 IDF 是计算该词语在文档集合中的重要程度,对于一个词,只在一篇文章中出现多次,那么该词就会有很高的 TF 以及 IDF,那么我们就认为这个词就是关键词.
TF-IDF 本质上是综合了 TF 和 IDF 的特性,对关键词加以区分的算法.
# 简单案例
这里采用 Python 的 Sklearn 包为例 (取自网上 Demo).
#导入特征提取包,第一个用于计数,第二个用于计算词频 | |
from sklearn.feature_extraction.text import CountVectorizer | |
from sklearn.feature_extraction.text import TfidfTransformer | |
x_train = ['TF-IDF 主要 思想 是', | |
'算法 一个 重要 特点 可以 脱离 语料库 背景', | |
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要'] | |
x_test=['原始 文本 进行 标记', | |
'主要 思想'] | |
#该类会将文本中的词语转换为词频矩阵,矩阵元素 a [i][j] 表示 j 词在 i 类文本下的词频 | |
vectorizer = CountVectorizer(max_features=10) | |
#该类会统计每个词语的 tf-idf 权值 | |
tf_idf_transformer = TfidfTransformer() | |
#将文本转为词频矩阵并计算 tf-idf | |
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train)) | |
#将 tf-idf 矩阵抽取出来,元素 a [i][j] 表示 j 词在 i 类文本中的 tf-idf 权重 | |
x_train_weight = tf_idf.toarray() | |
#对测试集进行 tf-idf 权重计算 | |
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test)) | |
x_test_weight = tf_idf.toarray() # 测试集 TF-IDF 权重矩阵 | |
# 获取关键词集 | |
def get_keywords(matrixArray, keywordsArray): | |
return [keywordsArray[index] for index in range(len(matrixArray)) if matrixArray[index]>0] | |
print('输出x_train文本向量:') | |
print(x_train_weight) | |
print('输出x_test文本向量:') | |
print(x_test_weight) | |
for i in range(len(x_test_weight)): | |
print(f'测试集第{i}个文本的关键词是',get_keywords(x_test_weight[i], vectorizer.get_feature_names_out())) |
这里 x_train 代表我们采用了三个文本,x_test 用于测试.
- 首先我们载入包和训练集和测试集
- 接着采用计数类,将词语转化为词频矩阵。然后初始化一个用于计算 tf-idf 的类
- 将训练集导入其中进行训练。最后输出测试集中的关键词.

# 项目实战
# 项目背景:
采集 http://www.safehoo.com/Case/Case/Collapse 网站的数据,收集每段事故的标题,事故概况,事故原因,采取 TFIDF 算法计算出关键词.
# 数据采集
# 网址分析:
首先进入网址发现总共包含 668 条数据要采集,每页包含 30 条数据,通过翻页发现,该网站是由页码来控制网站展示的内容,在这里坍塌事故 - 案例分析 - 安全管理网 (safehoo.com) 表示的是携带最新数据的页码,其网址中包含的页码为 23, 进一步分析,发现其尾页的页码为 1. 同时,页面是通过 a 标签的 href 链接进行跳转到事故的详情页的,在详情页中数据都是保存在类名为 c_content_text 的 div 标签中。针对如上网站,设计如下爬取思路:
- 对携带页面的页面进行请求,解析网页,获取指向详情页的链接,将其保存在 EXCEL 中
- 对第一步爬取的详情页链接发起请求,对网页进行解析,将解析的结果以 EXCEL 保存.
# 爬虫程序撰写
这里使用 Python 撰写爬虫.
模块介绍:requests+re+etree+pandas+tqdm
- requests: 爬虫模块,主要用于向网站发起请求,获取网址的 HTML 文本
- **re:** 正则表达式模块,用于文本进行处理等操作
- **etree:** 将 HTML 文本转化为解析树的形式,以用于对网页的解析
- **pandas:** 数据处理模块,可将数据存入 EXCEL
- tqdm: 进度条
# 详情页爬取 | |
# requests 爬取网页 | |
import requests | |
# 解析网页 | |
from lxml import etree | |
# 正则表达式 | |
import re | |
# 将 dataframe (数据框) 导出成 excel | |
import pandas as pd | |
# 将代码执行过程以进度条展示 | |
from tqdm import tqdm | |
tempdict = { | |
# 存储的标题 | |
'title': [], | |
# 没用 | |
'dtype': [], | |
# 目标网址链接 | |
'urlhref': [] | |
} | |
headers = { | |
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56' | |
} | |
#对网址发起请求 | |
for i in tqdm(range(1,23)): | |
baseurl = 'http://www.safehoo.com' | |
url = baseurl + f'/Case/Case/Collapse/List_{i}.shtml' | |
#网址先包含了对浏览器的检测,要加入 headers | |
res = requests.get(url, headers=headers) | |
#转化格式,防止乱码出现 | |
res.encoding = 'utf-8' | |
html = etree.HTML(res.text) | |
a = html.xpath('//div[@class="childclass_content"]/li') | |
for i in a: | |
# 标题,进行异常检测 | |
try: | |
tempdict['title'].append(i.xpath('./a/text()')[0]) | |
except: | |
tempdict['title'].append(i.xpath('./a/font/text()')[0]) | |
# 类型 | |
tempdict['dtype'].append(re.sub(' ','',re.sub('[A-Za-z0-9\!\%\[\]\,\。]','',i.xpath('./text()')[0]))) | |
# 地址 | |
tempdict['urlhref'].append(baseurl+i.xpath('./a/@href')[0]) | |
#将数据转化为数据框格式 | |
df = pd.DataFrame(tempdict) | |
#将数据保存到 excel 里面 | |
df.to_excel('output.xlsx', index=False) |
# 内容爬取 | |
import re | |
import pandas as pd | |
import requests | |
from tqdm import tqdm | |
from lxml import etree | |
df = pd.read_excel('output.xlsx') | |
url = df['urlhref'] | |
df['result'] = None | |
headers = { | |
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56' | |
} | |
for i in tqdm(range(len(url))): | |
res = requests.get(url[i], headers=headers) | |
res.encoding = 'utf-8' | |
html = etree.HTML(res.text) | |
try: | |
item = html.xpath('//*[@id="prt2"]/div')[0].xpath('string(.)') | |
result = re.sub(' ', '', re.sub('\r\n ', '', item)) | |
except: | |
result = None | |
df['result'][i] = result | |
df.to_excel('result.xlsx', index=False) |
总共获取了 648 条数据.
# 数据预处理
到这里,我们获得了 如图所示数据,但是其中仍然包含大量的 HTML 文本,同时暂时还没将原因区分
出来,因此,接下来需要采取正则的操作将文本规范化,同时将事故原因抽取出来。由于该网站的数据是以文档加 pdf 的形式展示的,因此在第一步先对 pdf 形式的文本进行一个去除.
直接采用 pandas 中 notnull () 的方法。去除后还剩下 617 条文本.
根据网站结构,我们可以知道,这里面的包含了很多结构化的信息,同时也包含了对原因的展示,在这里定义了一个函数,对网站的空字符,换行符以及 Unicode 编码进行了一个去除,接着针对标题所带的索引进行分块,然后依次遍历检索,若其中包含原因,那么该快就是对于该事故的原因解释.
def split_function(text): | |
type_list = ["一", "二", "三", "四", "五", "六", "七", "八", "九", "十"] | |
result = "" | |
text = text.replace('\r','').replace('\n','').replace('\t','').replace('\u3000', '') | |
for i in range(len(type_list)): | |
try: | |
temptext = re.findall(f"{type_list[i]}、(.*?){type_list[i+1]}、", text)[0] | |
if "概况" in temptext or "结果" in temptext: | |
result = result + "事故概况:" + temptext.split('。')[0] | |
if "原因" in temptext: | |
result = result + "事故原因" + temptext | |
except: | |
break | |
if "概况" not in result: | |
try: | |
result = "事故概况:" + text.split("。")[0] + result | |
except Exception as e: | |
print(e) | |
if "原因" not in result: | |
try: | |
result = result + "事故原因" + ''.join(text.split("。")[1:]) | |
except Exception as e: | |
print(e) | |
return result | |
def get_reason(text): | |
try: | |
if(text[1]==''): | |
return text[2] | |
else: | |
return text[1] | |
except: | |
return None |
这里已经成功的将原因抽取出来了.
接着对筛取的结果进行进一步处理,最后将其转化为 EXCEL 存储.
# 分词与词典构建
由于中文在处理时,首先第一步是要对其进行分词操作,同时由于新词的出现,因此需要用到行业相关的专用词典.
由于 python 在分词时需要用到 txt 格式的文件作为分词,目录,所以这里需要先将.scel 格式的文件转化为 txt 格式的文件
.scel 格式采用 Unicode 编码了汉字、拼音.
这里直接采取别人的解析程序:
# -*- coding: utf-8 -*- | |
import struct | |
import os | |
# 拼音表偏移 | |
startPy = 0x1540; | |
# 汉语词组表偏移 | |
startChinese = 0x2628; | |
# 全局拼音表 | |
GPy_Table = {} | |
# 解析结果 | |
# 元组 (词频,拼音,中文词组) 的列表 | |
# 原始字节码转为字符串 | |
def byte2str(data): | |
pos = 0 | |
str = '' | |
while pos < len(data): | |
c = chr(struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]) | |
if c != chr(0): | |
str += c | |
pos += 2 | |
return str | |
# 获取拼音表 | |
def getPyTable(data): | |
data = data[4:] | |
pos = 0 | |
while pos < len(data): | |
index = struct.unpack('H', bytes([data[pos],data[pos + 1]]))[0] | |
pos += 2 | |
lenPy = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
pos += 2 | |
py = byte2str(data[pos:pos + lenPy]) | |
GPy_Table[index] = py | |
pos += lenPy | |
# 获取一个词组的拼音 | |
def getWordPy(data): | |
pos = 0 | |
ret = '' | |
while pos < len(data): | |
index = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
ret += GPy_Table[index] | |
pos += 2 | |
return ret | |
# 读取中文表 | |
def getChinese(data): | |
GTable = [] | |
pos = 0 | |
while pos < len(data): | |
# 同音词数量 | |
same = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
# 拼音索引表长度 | |
pos += 2 | |
py_table_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
# 拼音索引表 | |
pos += 2 | |
py = getWordPy(data[pos: pos + py_table_len]) | |
# 中文词组 | |
pos += py_table_len | |
for i in range(same): | |
# 中文词组长度 | |
c_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
# 中文词组 | |
pos += 2 | |
word = byte2str(data[pos: pos + c_len]) | |
# 扩展数据长度 | |
pos += c_len | |
ext_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
# 词频 | |
pos += 2 | |
count = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] | |
# 保存 | |
GTable.append((count, py, word)) | |
# 到下个词的偏移位置 | |
pos += ext_len | |
return GTable | |
def scel2txt(file_name): | |
print('-' * 60) | |
with open(file_name, 'rb') as f: | |
data = f.read() | |
print("词库名:", byte2str(data[0x130:0x338])) # .encode('GB18030') | |
print("词库类型:", byte2str(data[0x338:0x540])) | |
print("描述信息:", byte2str(data[0x540:0xd40])) | |
print("词库示例:", byte2str(data[0xd40:startPy])) | |
getPyTable(data[startPy:startChinese]) | |
getChinese(data[startChinese:]) | |
return getChinese(data[startChinese:]) | |
# scel 所在文件夹路径 | |
in_path = './专业词词库' | |
# 输出词典所在文件夹路径 | |
out_path = './词库' | |
fin = [fname for fname in os.listdir(in_path) if fname[-5:] == ".scel"] | |
for f in fin: | |
try: | |
for word in scel2txt(os.path.join(in_path, f)): | |
file_path=(os.path.join(out_path, str(f).split('.')[0] + '.txt')) | |
# 保存结果 | |
with open(file_path,'a+',encoding='utf-8')as file: | |
file.write(word[2] + '\n') | |
os.remove(os.path.join(in_path, f)) | |
except Exception as e: | |
print(e) | |
pass |
接着在对上述生成的 txt 文本进行一个合并操作,最终生成了一个自定义词典.
然后采用 jieba 分词,将其转化为词的形式.
# 数据集处理
采取上述爬取的数据集和人工收集到的第二份数据集进行合并,由于分析对象选取的是 2007 年以后,所以针对其进行了进一步的筛选操作。还剩余 425 条数据.
# 模型导入
#TfidfVectorizer 为上述 CountVectorizer,TfidfTransformer 的集合 | |
vector = TfidfVectorizer(stop_words=stoplist, vocabulary = vocab) | |
tf_idf = vector.fit_transform(corpus) |
由于文章包含大量描述性的话语,同时存在多个词语指代同一词语的现象,因此,在此基础上,对停用词词典进行进一步调整,然后根据 top50 的词频,将其跟原因相关的词汇进行分类,将原因分为如下四类:
- 安全因素:' 安全生产 ',' 安全管理 ',' 安全隐患 ',' 培训 ',' 安全生产工作 ',' 现场安全管理 ',' 教育'
- 管理因素:' 管理 ',' 监理 ',' 组织 ',' 落实 ',' 履行 ',' 监督 ',' 协调 ',' 混乱 ',' 监督管理 ',' 审批'
- 工作因素:' 检查 ',' 排查 ',' 违反 ',' 整改 ', ' 拆除 ',' 调查 ',' 发现 ',' 验收'
- 其他因素 ' 隐患 ',' 分包 ',' 救援 ',' 临时'
同时将其词频分布以词云图的形式展现。

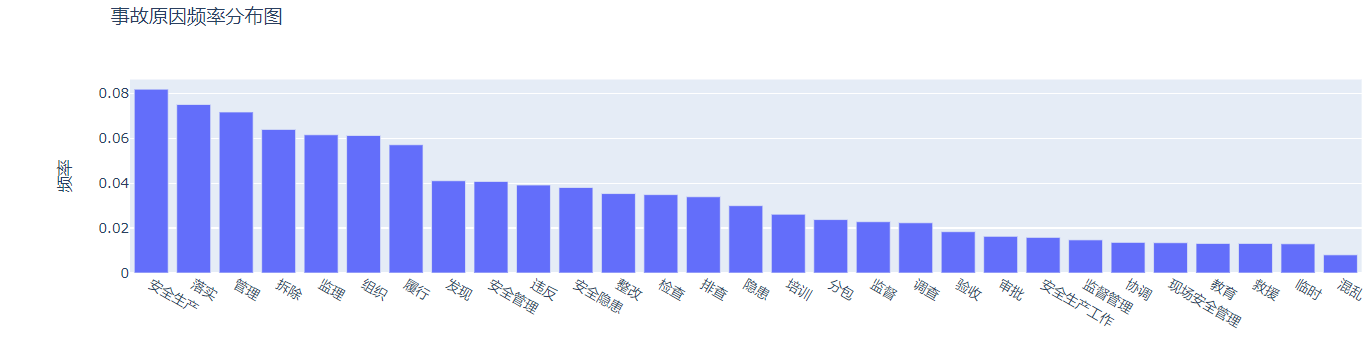
最后将其结果以上述关键词进行一个分类。
