# 关联挖掘
# 基本概念
频繁项集:n 项的集合。
支持度:代表 A、B 同时出现的概率,如果概率小,那么说明 A 与 B 的关系不大,如果 A、B 总是同时出现,那么说明他们是相关的。
置信度:包含 A 的数据集中包含 B 的百分比。
# Apriori 算法
使用候选项集找频繁项集
核心思想,只要一个项集是非频繁的,那么包含他的项集就都是非频繁的。
# 算法实现
关联矩阵转布尔矩阵
data = final_data.copy() | |
def map_func(x): | |
if x == 0: | |
return False | |
else: | |
return True | |
for i in data.columns: | |
data[i] = data[i].map(lambda x:map_func(x)) |
计算关联规则
from mlxtend.preprocessing import TransactionEncoder | |
from mlxtend.frequent_patterns import apriori | |
#利用 Apriori 找出频繁项集 | |
freq = apriori(data, min_support=0.1, use_colnames=True) | |
#导入关联规则包 | |
from mlxtend.frequent_patterns import association_rules | |
#计算关联规则 | |
result = association_rules(freq, metric="confidence", min_threshold=0.8) |
这里采用最小支持度为 0.1,最小置信度为 0.8
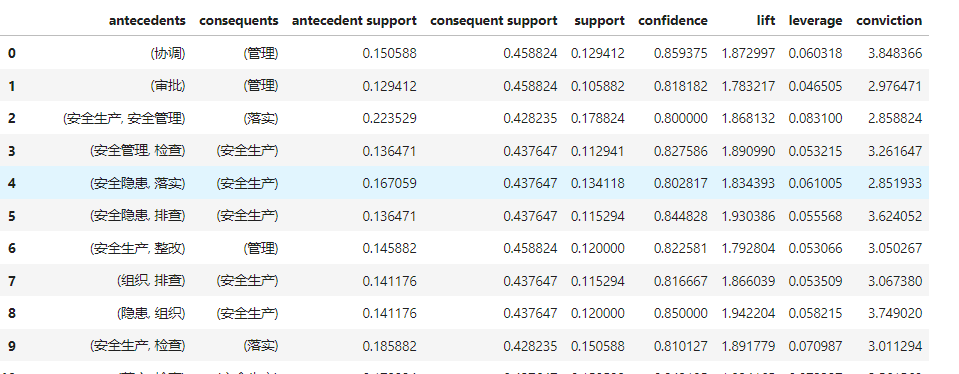
会得到如下 51 项关联规则,其中 support 代表支持度,confidence 代表提升度。
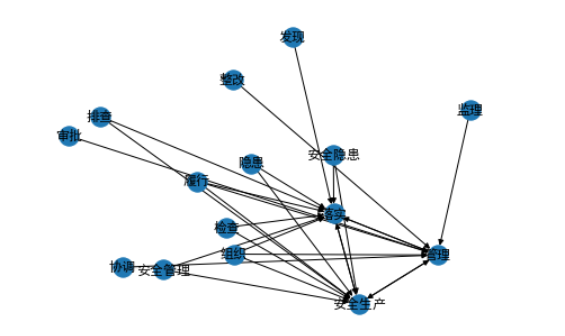
画图: